Bayesian Bandits: Thompson Sampling with Implementation and Regret Analysis
Thompson Sampling: At any round of the Thompson Sampling, we try to sample a bandit environment from the bandit space that is most likely to be close to the one we are dealing with right now, given the history of the previous rounds. So, we are in fact building a posterior distribution $Q_{t}(v | X_{t-1}, A_{n-1},\cdots, ,X_{1}, A_{1})$ where $v$ is the bandit environment and $A_{t}$ is the action taken at round $t$ and $X_{t}$ is the reward revealed after action $A_{t}$. For brevity, let’s define $H_{t} = (X_{t}, A_{t},\cdots, ,X_{1}, A_{1})$ to be the history of exploration-exploitation and rewards. So, this approach returns a policy $\pi = (\pi_{t})_{t=1}^{\infty}$ so that,
where,
Ties are broken arbitrarily.
Pseudocode:
for $t = 1, 2, \cdots , n$ do
$\quad\quad$sample $v_{t}$ from $Q_{t}(.|H_{t-1})$
$\quad\quad$choose $A_{t} = \arg \max_{1 \leq i \leq k} \mu_{i}(v_{t})$
$\quad\quad$observe reward $X_{t}$
$\quad\quad$update $H_{t} = (X_{t}, A_{t}) \oplus H_{t-1}$
end for
Here, $\oplus$ means concatenation.
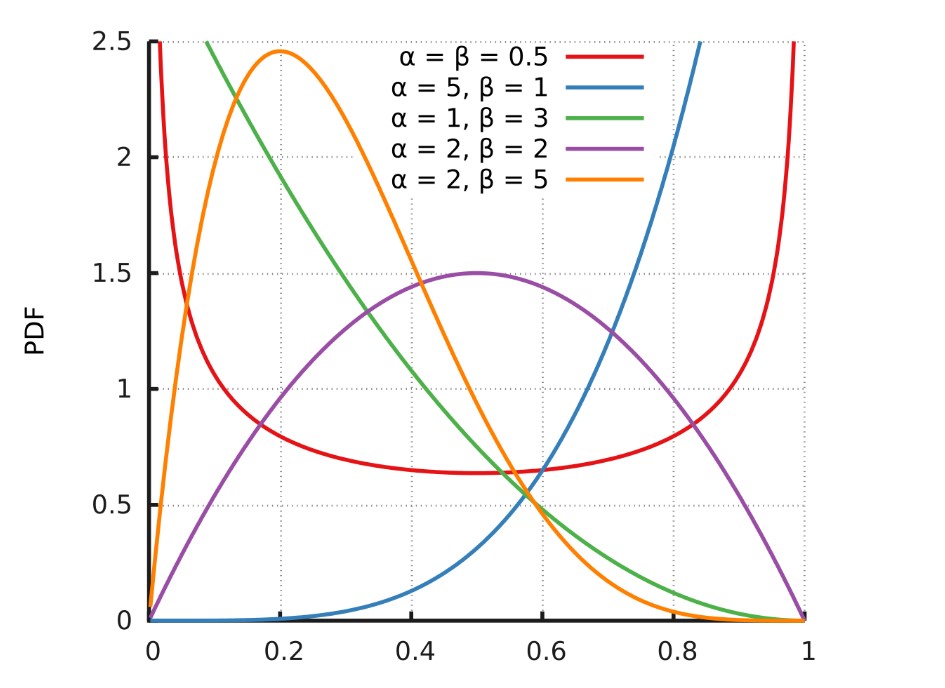
A very easy example for Bernoulli Bandits: For every arm, we keep track of two variables $(\alpha, \beta)$. $\alpha$ means the number of rewards and $\beta$ is the number times you got no rewards. We use a Beta Distribution to sample a mean reward for this arm which is likely to be close to $\frac{\alpha}{\alpha + \beta}$. In this way, we get an estimate for the mean rewards of each arm. And this is the bandit $v_{t}$ which is mentioned in the pseudocode. We simply choose the best arm of $v_{t}$.
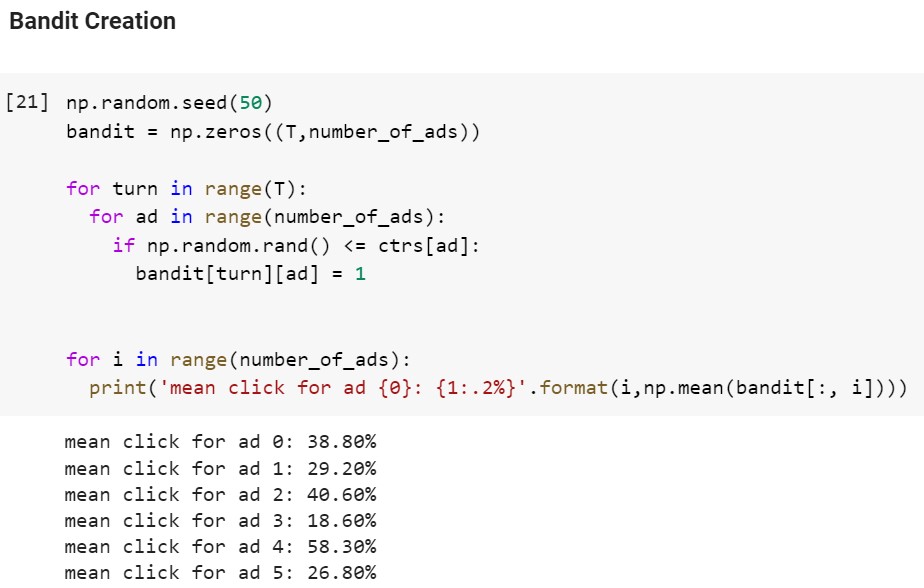
Suppose, we are talking about ad recommendation. We have $k$ ads to render to a user. For each ad, we keep track of $(\alpha, \beta)$. We start with the beta distribution with $(\alpha = 0, \beta = 0)$ as prior. An implementation of Thompson Sampling in this scenario is shown below:

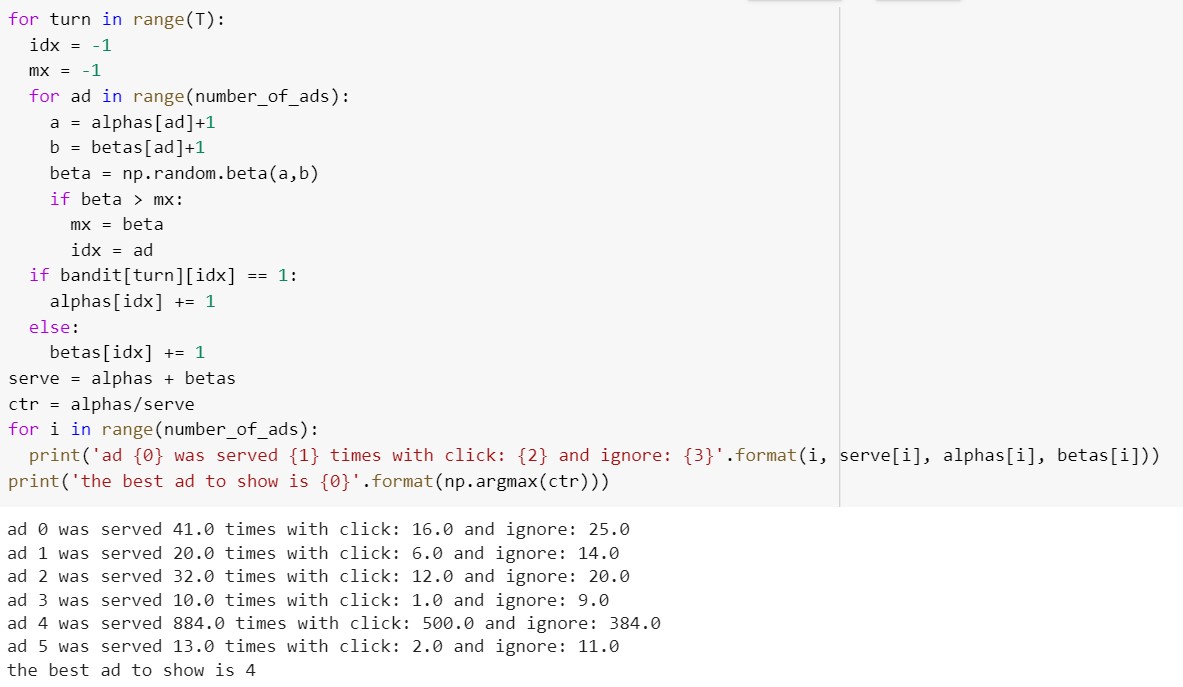
Bayesian Regret Analysis: We will discuss the worst case Bayesian regret of Thompson Sampling for Bernoulli Bandits with 0-1 rewards and Gaussian bandits with 1-sub Gaussian arms.
If the bandit has only 0-1 rewards, then for a particular arm, if it’s played $T_{i}(t-1)$ times up to round $t$, then from, Hoeffding’s Inequality we know that,
If the bandit is 1-sub Gaussian, then we can say,
So, in both cases, we can say that for all arms $i$ and for all rounds $t$,
holds for a good probability in the order of $1-2\delta$ for each $i$ and $t$ with $\delta$ arbitrality close to 0. Such as, taking $\delta = \frac{1}{n^{2}}$. Let’s define this event to be the good event $G$. The bad event $G^{c}$ is then the event when any of the arms violate this property at any round. So,
Let’s define $U_{t}(i) = \mu_{i}(t-1) + \sqrt{\frac{1}{\max(1,T_{i}(t-1))}\log{\frac{1}{\delta}}}$ which is the upper confidence bound of UCB. We know that, the Bayesian Regret can be expressed using the tower rule of conditional expectation with respect to the history $H_{t-1}$. So,
Let’s focus on the inner conditional expectation,
The second line follows from the fact that,
The best arm $A^{*}$ given the history is actually identically distributed as the best arm of the most plausible bandit given the history. So,
So,
Then,
Let’s focus on $\mathbb{E}[R_{n} | G]$.
Because, the left summand is negative in the good scenario. So,
We know that, the arithmetic mean is less than the quadratic mean. So,
So,
Since, typically $n$ is substantially larger than $k$ and since, $\delta = \frac{1}{n^{2}}$,